了解Java NIO
NIO最早出现在JDK1.4中,NIO 弥补了原来的 I/O 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。通过定义包含数据的类,以及通过以块的形式处理这些数据,NIO 不用使用本机代码就可以利用低级优化,这是原来的 I/O 包所无法做到的。
NIO带来的好处
NIO的创建目的是为了让Java程序员可以实现高速I/O而无需编写自定义的本机代码。NIO将最耗时的I/O操作(即填充和提取缓冲区)转移回操作系统,背后可以采用基于操作系统底层的IO读取模型,因而可以极大地提高速度。
NIO与传统的IO有什么不同
原来的I/O库(在 java.io.*中)与NIO最重要的区别是数据打包和传输的方式。正如前面提到的,原来的I/O以流的方式处理数据,而NIO以块的方式处理数据。
面向流的I/O系统一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。为流式数据创建过滤器非常容易。链接几个过滤器,以便每个过滤器只负责单个复杂处理机制的一部分,这样也是相对简单的。不利的一面是,面向流的I/O通常相当慢。
一个面向块的I/O系统以块的形式处理数据。每一个操作都在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多。但是面向块的I/O缺少一些面向流的I/O所具有的优雅性和简单性。
NIO的核心
通道和缓冲是NIO的核心,通道可以看作是IO包中的流的模拟,当需要获取或者写入数据时,需要通过Channel对象传入或者传出,中间使用Buffer等的缓冲区,Buffer对象实质上是一个容器对象,发给通道的数据都必须先放到缓冲区中,同样,从通道中读取数据必须先读到缓冲区中。
NIO的核心之缓冲区
Buffer是一个对象,它包含一些要写入或者刚读出的数据。在NIO中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中,您将数据直接写入或者将数据直接读到Stream对象中。
在 NIO 库中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的。在写入数据时,它是写入到缓冲区中的。任何时候访问 NIO 中的数据,您都是将它放到缓冲区中。
缓冲区实质上是一个数组。通常它是一个字节数组,但是也可以使用其他种类的数组。但是一个缓冲区不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
Java提供的多种Buffer类型:
- ByteBuffer
- CharBuffer
- ShortBuffer
- IntBuffer
- LongBuffer
- FloatBuffer
- DoubleBuffer
每一个 Buffer 类都是 Buffer 接口的一个实例。 除了 ByteBuffer,每一个 Buffer 类都有完全一样的操作,只是它们所处理的数据类型不一样。因为大多数标准 I/O 操作都使用 ByteBuffer,所以它具有所有共享的缓冲区操作以及一些特有的操作。
NIO的核心之通道
Channel是一个对象,可以通过它读取和写入数据。拿NIO与原来的I/O做个比较,通道就像是流。
正如前面所说的,所有数据都通过Buffer对象来处理。你永远不会将字节直接写入通道中,相反,你需要把数据写入包含一个或者多个字节的缓冲区。同样,您不会直接从通道中读取字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
通道与流的不同之处在于通道是双向的。而流只是在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类), 而 通道 可以用于读、写或者同时用于读写。
因为它们是双向的,所以通道可以比流更好地反映底层操作系统的真实情况。特别是在 UNIX 模型中,底层操作系统通道是双向的。
NIO实践
首先看一个文件读取的例子:
|
|
程序清楚的显示了读取文件的过程,首先创建一个输入流,然后从FileInputStream中获取一个通道,在创建一个buffer缓冲区,然后就可以通过缓冲区读取数据了。我们不需要告诉通道要读多少数据到缓冲区中。每一个缓冲区都有复杂的内部统计机制,它会跟踪已经读了多少数据以及还有多少空间可以容纳更多的数据,后面我们会对缓冲区内部机制进行更深分析。
然后看一个文件写入的例子:
|
|
和文件读取的例子大致相同,创建输出流,获取通道,创建缓冲区,put()方法用于向缓冲区输入数据。flip()方法让缓冲区可以将新读入的数据写入另一个通道。
当fc.read(buffer)返回-1时,表示数据已经读取完毕。接下来看一个如何把一个文件的内容复制到一个新的文件:
|
|
上面的结合前面的写入和读取的例子来解释就很简单了,clear()是清理缓冲区中的数据的方法,在从输入通道读入缓冲区之前,我们调用 clear()方法来清理缓冲区的数据。
缓冲区内部机制详解
本节将介绍 NIO 中两个重要的缓冲区组件:状态变量和访问方法 (accessor)。
状态变量是前面提到的”内部统计机制”的关键。每一个读/写操作都会改变缓冲区的状态。通过记录和跟踪这些变化,缓冲区就可能够内部地管理自己的资源。
在从通道读取数据时,数据被放入到缓冲区。在有些情况下,可以将这个缓冲区直接写入另一个通道,但是在一般情况下,您还需要查看数据。这是使用访问方法get()来完成的。同样,如果要将原始数据放入缓冲区中,就要使用访问方法put()。
状态变量
可以用三个值指定缓冲区在任意时刻的状态:
positionlimitcapacity
这三个变量一起可以跟踪缓冲区的状态和它所包含的数据。下面我们将详细分析每一个变量,还要介绍它们如何适应典型的读/写(输入/输出)进程。在这个例子中,我们假定要将数据从一个输入通道拷贝到一个输出通道。
Position
您可以回想一下,缓冲区实际上就是美化了的数组。在从通道读取时,您将所读取的数据放到底层的数组中。 position 变量跟踪已经写了多少数据。更准确地说,它指定了下一个字节将放到数组的哪一个元素中。因此,如果您从通道中读三个字节到缓冲区中,那么缓冲区的 position 将会设置为3,指向数组中第四个元素。
同样,在写入通道时,您是从缓冲区中获取数据。 position 值跟踪从缓冲区中获取了多少数据。更准确地说,它指定下一个字节来自数组的哪一个元素。因此如果从缓冲区写了5个字节到通道中,那么缓冲区的 position 将被设置为5,指向数组的第六个元素。
Limit
limit变量表明还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)。
position 总是小于或者等于 limit。
Capacity
缓冲区的capacity表明可以储存在缓冲区中的最大数据容量。实际上,它指定了底层数组的大小 ― 或者至少是指定了准许我们使用的底层数组的容量。
注意:limit 决不能大于 capacity。
初始状态
我们首先观察一个新创建的缓冲区。出于需要,我们假设这个缓冲区的总容量为8个字节。 Buffer 的状态如下所示:

回想一下,limit决不能大于capacity,此例中这两个值都被设置为8。我们通过将它们指向数组的尾部之后(如果有第8个槽,则是第8个槽所在的位置)来说明这点。
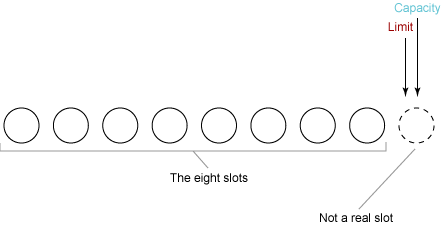
position 设置为0。如果我们读一些数据到缓冲区中,那么下一个读取的数据就进入slot0。如果我们从缓冲区写一些数据,从缓冲区读取的下一个字节就来自slot0。position设置如下所示:

开始读取数据
现在我们可以开始在新创建的缓冲区上进行读/写操作。首先从输入通道中读一些数据到缓冲区中。第一次读取得到三个字节。它们被放到数组中从position开始的位置,这时position被设置为 0。读完之后,position就增加到3,如下所示:
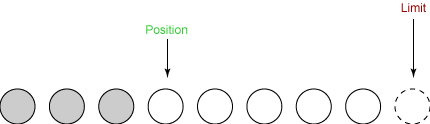
再次读取数据
我们从输入通道读取另外两个字节到缓冲区中。这两个字节储存在由position所指定的位置上,position因而增加2:
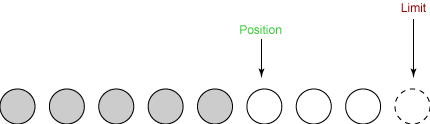
输出数据到通道
还记得flip方法发,现在我们要将数据写到输出通道中。在这之前,我们必须调用flip()方法。这个方法做两件非常重要的事:
- 它将
limit设置为当前position。 - 它将
position设置为0。
前面的图显示了在flip之前缓冲区的情况。下面是在flip之后的缓冲区:
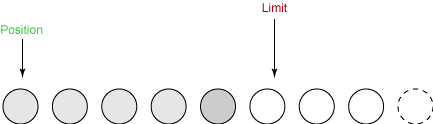
我们现在可以将数据从缓冲区写入通道了。position被设置为0,这意味着我们得到的下一个字节是第一个字节。limit已被设置为原来的position,这意味着它包括以前读到的所有字节,并且一个字节也不多。
初始写入
在初始写入时,我们从缓冲区中取四个字节并将它们写入输出通道。这使得position增加到4,而limit不变,如下所示:
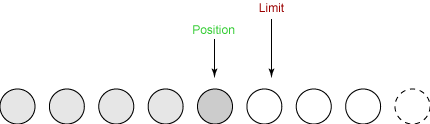
最后一个写入
我们只剩下一个字节可写了。limit在我们调用flip()时被设置为5,并且position不能超过limit。所以最后一次写入操作从缓冲区取出一个字节并将它写入输出通道。这使得position增加到5,并保持limit不变,如下所示:
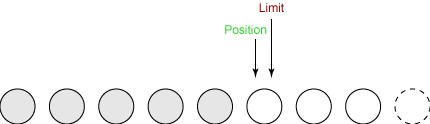
结尾
最后一步是调用缓冲区的clear()方法。这个方法重设缓冲区以便接收更多的字节。Clear做两种非常重要的事情:
它将limit设置为与capacity相同。
它设置position为0。
下图显示了在调用clear()后缓冲区的状态:
回显服务器
在讲完 NIO 内部机制后,我们使用Java NIO来构建一个回显服务器,这个回显服务器使用socket监听接口,然后接收客户端的连接,然后把客户端发过来的数据原封不动的发回去。
|
|
上面是一个使用select模型和NIO构建的一个简单服务器,它监听服务器的12345端口,当客户端连接到12345端口时,它会建立与客户端的连接,并且可以把客户端的消息原封不动的发送回去,你可以使用多个客户端与服务器建立连接,服务器也可以正确的把消息返回给你,注意:服务器一直使用一个进程来建立连接,它没有建立新的进程,因此也就没有进程或者线程切换所带来的消耗!,在大量的客户端同时与服务器建立连接是他才能显示出威力,如果没有大量的连接,建议还是使用普通的多线程或者多进程服务器,因为它们比较简单,性能也没有太大区别。
代码详解
Selector
在我们边写的程序中,使用的Selector对象使用程序的核心,它是我们注册对各种IO事件感兴趣的地方,当有IO事件发生时,这个对象会告诉我们所发生的事件,
Selector selector = Selector.open();用于创建一个Selector对象,你可以将不同的通道对象注册到selector中,方法就是通道自身的register方法,参数是Selector类的的实例和你感兴趣的事件。
注册ServerSocketChannel到Selector上
首先我们打开一个ServerSocketChannel对象,并且把它绑定到通信的端口上,注意把这个对象设置为非阻塞的,这个非常重要,如果没有设置的话,可能程序无法工作。
第二步是把这个ServerSocketChannel对象注册到创建的Selector对象上,如代码所示。调用register方法后,会返回一个SelectionKey,它代表通道在Selector的注册,当发生相应的传入事件时,他是通过返回对应的SelectionKey来进行的,当你需要取消通道的注册时,可以通过SelectionKey.cancel()方法来取消。
|
|
循环监听连接
可以调用Selector的select()方法。这个方法会阻塞,直到至少有一个已注册的事件发生。当一个或者更多的事件发生时,select() 方法将返回所发生的事件的数量。
然后你可以获取他的一个迭代器,通过迭代器并依次处理每个SelectionKey来处理事件。对于每一个SelectionKe,您必须确定发生的是什么 I/O 事件,以及这个事件影响哪些 I/O 对象。
|
|
创建新的连接
当发生SelectionKey.OP_ACCEPT事件时,代表有一个连接将要建立,我们可以直接调用accept接受这个连接,这里不会阻塞,因为我们知道有一个连接来了,当然不会阻塞,创建完连接后把连接注册到我们的Selector上,并设置对应的监听事件。注意:这个连接也需要设置为非阻塞的。
|
|
删除处理完的SelectionKey
在处理完SelectionKey对应的事件后,我们需要删除它,如果我们没有删除处理过的键,那么它仍然会在主集合中以一个激活的键出现,这会导致我们尝试再次处理它。我们调用迭代器的remove()方法来删除处理过的SelectionKey。
继续循环…
每次返回主循环,我们都要调用select的Selector()方法,并取得一组SelectionKey。每个键代表一个I/O事件。我们处理事件,从选定的键集中删除SelectionKey,然后返回主循环的顶部。
特殊情况
还有需要注意的一个点是代码中的这个部分:
有的人可能会把它写成像下面这样:
|
|
这个是不正确的,当客户端粗暴的关闭连接时,服务器也应该关闭连接,如果没有关闭连接的话,在每次selectedKeys.iterator返回的时候都会返回当前socket可读的事件,这样会浪费服务器的资源,做不必要的操作。
结束
好了,这篇文章我们着重讲了NIO库的使用以及内部特性,在一些新特性(例如文件锁定和字符集)提供新功能的同时,许多特性在优化方面也非常优秀。
在基础层次上,通道和缓冲区可以做的事情几乎都可以用原来的面向流的类来完成。但是通道和缓冲区允许以快得多的方式完成这些相同的旧操作 ― 事实上接近系统所允许的最大速度。
不过NIO最强大的长度之一在于,它提供了一种在Java语言中执行进行输入/输出的新的(也是迫切需要的)结构化方式。随诸如缓冲区、通道和异步IO这些概念性(且可实现的)实体而来的,是我们重新思考Java程序中的IO过程的机会。这样,NIO甚至为我们最熟悉的IO过程也带来了新的活力,同时赋予我们通过和以前不同并且更好的方式执行它们的机会。