前言
在 Java 中,IO 是 Java 的一个重要组成,大约有80个标准 Java IO 类可以用来操作 IO 流,注意我的意思是 标准的IO流 ,JDK1.4引入的 NIO 和其相关的类并没有计算在内。因此,操作 IO 的方式多种多样,我们接下来会对 IO 进行一个大概的描述。
Java 中操作 IO 的类大概可以分为四组,分别是:
- 基于字节操作的流:InputStream 和 OutputStream:
- 基于字符操作的流:Writer 和 Reader
- 基于文件操作的流:File
- 基于网络连接的流:Socket
在这里,我们可以把上面4个分成两组,1,2 为第一组,它们关注的是数据处理的格式,3,4 为第二组,它们关注的是数据传输的方法,两种方式分别影响我们操作 IO 的效率,所以我们的关注点也在这两个方面。
基础的处理流
这里有一张大致的关于 Java IO 类的结构图,我们先来看一下:
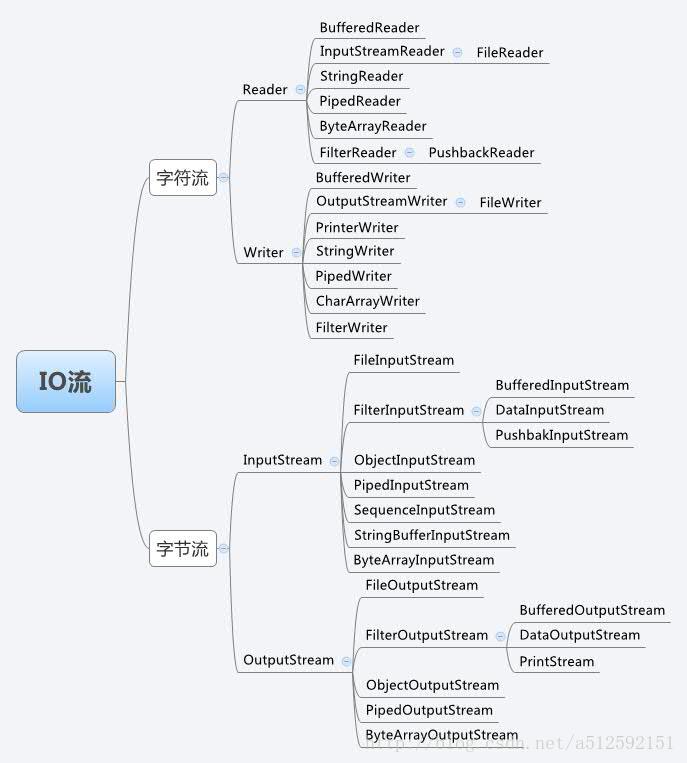
这些都是基础的处理流,还有一些比较深入的基于 IO 的处理类,我们会介绍类的用法及其原理,以及提高 IO 工作效率的方法。
字节流
操作字节流的主要是 InputStream 和 OutputStream 这两个接口,它们定义了基本的操作数据的方法,我们来介绍它们的常用实现类。
ByteArrayInputStream 和 ByteArrayOutputStream 类
我们可以从 InputStream 或 Reader 中读取数组,用 ByteArrayInputStream 或者 CharArrayReader 封装字节或者字符数组从数组中读取数据。通过这种方式字节和字符就可以以数组的形式读出了。
|
|
ByteArrayOutputStream 这个类可以把数据封装在一个 ByteArrat 数组中,常与 ByteArrayInputStream 结合使用,一个常见的例子是使用序列化深度克隆 Java对象的时候。
|
|
注意:这里用了JDK1.7的新语法,这样可以省去我们需要手动关闭流和处理异常的过程。
PipedOutputStream 和 PipedInputStream 类
通过 Java IO 中的 PipedOutputStream 和 PipedInputStream 创建管道,管道主要多个线程数据流的传输,一个线程可以通过 PipedOutputStream 写入数据,另外的线程可以通过 PipedInputStream 读取数据,就像是从文本读取创建的输入流一样。注意:这里读取和写入的线程必须是不一样的,因为 read() 方法和 write() 方法调用时会导致流阻塞,这意味着如果你尝试在一个线程中同时进行读和写,可能会导致线程死锁。
BuffereddInputStream 和 BuffereddOutputStream 类
我们操作流的时候通常不是操作原生的 InputStream 或者 OutputStream 流,通常用缓冲流来包装原生的流,然后在缓存流上进行读取获取或者写入,因为一次读取(写入)一个字节(字符)是很耗费资源,所以使用缓冲包装流,这样可以对多个字节(字符)进行操作,这样可以加快效率。例如:
|
|
字节流总结
我们使用的大多是字节流接口的方法,当我们使用流的方式都差不多,只不过数据输出的地方不同,流最终写到什么地方必须要指定,要么是写到磁盘要么是写到网络中,其实从上面的类图中我们发现,写网络实际上也是写文件,只不过写网络还有一步需要处理就是底层操作系统再将数据传送到其它地方而不是本地磁盘。
字符流到字节流的转换
字节流一般是真正与系统底层交互的流,不管是保存到磁盘还是通过网络传输出去,都是用的字节,所以操作的一般都是字节流,那字符流的出现是干啥的呢?因为在我们写代码的时候主要使用的还是字符流,Java 使用 Unicode 存储字符串,在我们对 String 进行操作时需要把底层的字节通过一定的编码转换成字符流,这里的转换编码表有许多,你可以选择合适的码表进行转换,注意:字符到字节,以及字节到字符需要用相同的码表,一般的乱码问题都是由于两次使用的码表不一致而导致乱码的。这个问题在 Java EE 很常见,而且困扰了很多人,有兴趣的同学可以参考这篇文章《深入分析Java中的中文编码问题》。
我们一般使用 InputStreamReader 和 OutputStreamReader进行字节流和字符流的转换,这两个类是 Reader 和 Writer 的子类,就像这样来使用他们:
|
|
这里使用 utf-8 来编码字节流中的数据,当我们把字节流转换成字符流后,就可以使用字符流的操作方法了。
字符流
关于字符流我们不多讲,因为一些类操作与字节流中的操作相差并不大,只是操作的数据从 byte 转换成为了 char。有一些特殊的操作字符的类我们大致了解一下。
PrintWriter 类
PrintWriter 可以把格式化后的数据写入到底层 writer 中。比如,写入格式化成文本的int,long以及其他原始数据类型到输出流中,而非它们的字节数据。代码如下:
|
|
PrintWriter有更多种构造函数供使用者选择,他可以输出到文件、Writer以外,还可以输出到OutputStream中(而PrintStream只能把数据输出到文件和OutputStream)。
RandomAccessFile 类
RandomAccessFile允许你来回读写文件,也可以替换文件中的某些部分。FileInputStream和FileOutputStream没有这样的功能。
在RandomAccessFile的某个位置读写之前,必须把文件指针指向该位置。通过seek()方法可以达到这一目标。可以通过调用getFilePointer()获得当前文件指针的位置。例子如下:
|
|
read()方法返回当前RandomAccessFile实例的文件指针指向的位置中包含的字节内容。Java文档中遗漏了一点:read()方法在读取完一个字节之后,会自动把指针移动到下一个可读字节。这意味着使用者在调用完read()方法之后不需要手动移动文件指针。
|
|
与read()方法类似,write()方法在调用结束之后自动移动文件指针,所以你不需要频繁地把指针移动到下一个将要写入数据的位置。
磁盘IO
我们通常把数据存放在磁盘,而磁盘保存数据的方式则是文件,也就是说我们通过操作文件来修改磁盘的数据,文件也是操作系统和磁盘驱动器交互的一个最小单元。有一个地方需要注意的是 Java 中的 File 类,它只是一个与文件路径相关联的一个虚拟对象,它可能是一个文件或者是包含多个文件的目录,并不代表真实存在的文件对象,这个设计的目的是什么呢?
因为大部分情况下,我们并不关心这个文件是否真的存在,而是关心这个文件到底如何操作。例如我们手机里通常存了几百个朋友的电话号码,但是我们通常关心的是我有没有这个朋友的电话号码,或者这个电话号码是什么,但是这个电话号码到底能不能打通,我们并不是时时刻刻都去检查,而只有在真正要给他打电话时才会看这个电话能不能用。也就是使用这个电话记录要比打这个电话的次数多很多。
那么什么时候会真正要检查一个文件是否存在呢?答案就是在真的读取这个文件时。例如 FileInputStream 类都是操作一个文件的接口,注意到在创建一个 FileInputStream 对象时,会创建一个 FileDescriptor 对象,其实这个对象就是真正代表一个存在的文件对象的描述,当我们在操作一个文件对象时可以通过 getFD() 方法获取真正操作的与底层操作系统关联的文件描述。例如可以调用 FileDescriptor.sync() 方法将操作系统缓存中的数据强制刷新到物理磁盘中。
具体磁盘读取文件的过程是怎样的呢?请看下图;
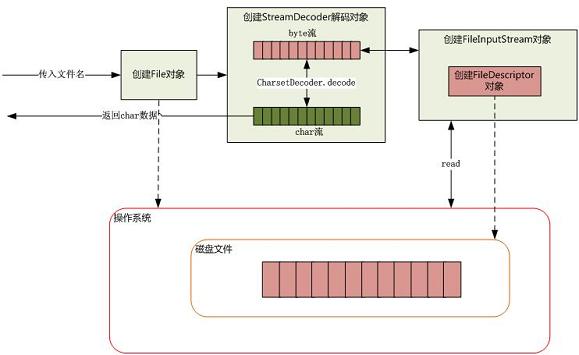
当传入一个文件路径,将会根据这个路径创建一个 File 对象来标识这个文件,然后将会根据这个 File 对象创建真正读取文件的操作对象,这时将会真正创建一个关联真实存在的磁盘文件的文件描述符 FileDescriptor,通过这个对象可以直接控制这个磁盘文件。由于我们需要读取的是字符格式,所以需要 StreamDecoder 类将 byte 解码为 char 格式(StreamDecoder也是把字节流转化到字符流的类),其中从磁盘驱动器上读取一段数据,是操作系统替我们完成的。
Socket IO
Socket 一般用来在各个主机间传输数据,也可以用来进行进程通信,它是描述计算机之间完成相互通信一种抽象功能,可以看做它是两个城市之间的交通工具,用它就在城市之间来回穿梭了,唯一确定 Socket 的是五元组,什么是五元组呢?就是(协议+源主机IP+源主机端口+目标主机IP+目标主机端口)。有了 Socket 我们就可以传输数据了。
## 建立通信链路
我们先看客户端:
|
|
客户端使用 Socket 实例来创建连接,操作系统将为这个 Socket 实例分配一个没有被使用的本地端口号,然后创建一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭。在 Socket 的实例返回前,会先进行 TCP 的三次握手协议,TCP 握手协议完成后,Socket 实例对象将创建完成,否则将抛出 IOException 错误。
再来看服务器端:
|
|
服务端将创建一个 ServerSocket 实例,ServerSocket 创建比较简单只要指定的端口号没有被占用,一般实例创建都会成功,同时操作系统也会为 ServerSocket 实例创建一个底层数据结构,这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下都是监听所有地址。
然后我们调用 accept() 方法时,将进入阻塞状态,等待客户端的请求。当一个新的请求到来时,将为这个连接创建一个新的套接字数据结构,该套接字数据的信息包含的地址和端口信息正是请求源地址和端口。这个新创建的数据结构将会关联到 ServerSocket 实例的一个未完成的连接数据结构列表中,注意这时服务端与之对应的 Socket 实例并没有完成创建,而要等到与客户端的三次握手完成后,这个服务端的 Socket 实例才会返回,并将这个 Socket 实例对应的数据结构从未完成列表中移到已完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的 TCP 连接。
## 数据传输
传输数据代码如下:
|
|
当连接已经建立成功,服务端和客户端都会拥有一个 Socket 实例,每个 Socket 实例都有一个 InputStream 和 OutputStream,正是通过这两个对象来交换数据。同时我们也知道网络 I/O 都是以字节流传输的。当 Socket 对象创建时,操作系统将会为 InputStream 和 OutputStream 分别分配一定大小的缓冲区,数据的写入和读取都是通过这个缓存区完成的。写入端将数据写到 OutputStream 对应的 SendQ 队列中,当队列填满时,数据将被发送到另一端 InputStream 的 RecvQ 队列中,如果这时 RecvQ 已经满了,那么 OutputStream 的 write 方法将会阻塞直到 RecvQ 队列有足够的空间容纳 SendQ 发送的数据。值得特别注意的是,这个缓存区的大小以及写入端的速度和读取端的速度非常影响这个连接的数据传输效率,由于可能会发生阻塞,所以网络 I/O 与磁盘 I/O 在数据的写入和读取还要有一个协调的过程,如果两边同时传送数据时可能会产生死锁,这个地方需要注意一下,在JDK1.4引入的NIO可以避免这个问题,我们后面会在介绍NIO。
总结
以上就是我们常用的的Java IO的一些相关的操作和类,在实际操作中我们要根据合适的情况来选择适合的类来操作流,这样我们的工作效率将会大大提高。